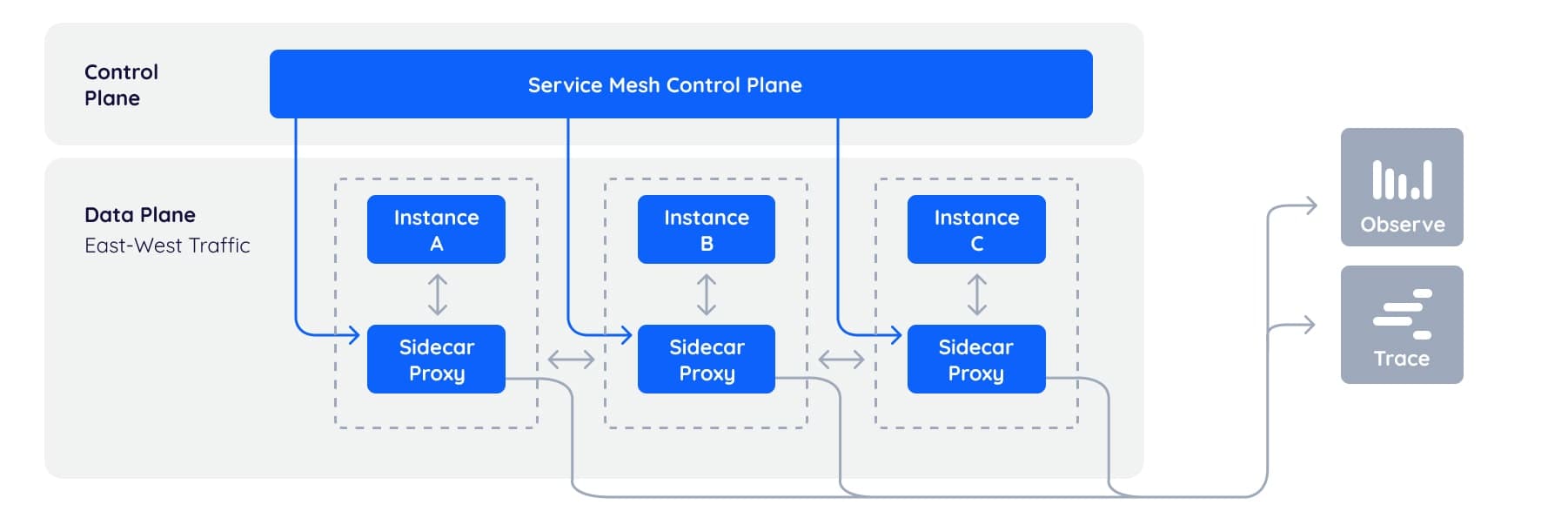
The Problem
- Unencrypted service-to-service communication leaving microservices vulnerable to man-in-the-middle attacks
- Each service implementing its own retry logic, circuit breakers, and timeouts creating inconsistencies
- No visibility into service dependencies, latency, or failure patterns in distributed systems
- Canary deployments and A/B testing requiring complex application code changes
- Service discovery and load balancing challenges as microservices scale and move across clusters
Our Solution
Automatic mTLS Encryption
Zero-trust security with transparent mutual TLS for all service-to-service communication
Intelligent Traffic Management
Advanced routing, load balancing, circuit breaking, and retry logic without code changes
Deep Observability
Distributed tracing, metrics, and logging for complete service mesh visibility
Service Discovery & Health
Automatic service registration, health checking, and load balancing
Progressive Delivery
Canary deployments, blue/green releases, and traffic splitting with percentage-based rollouts
Policy Enforcement
Fine-grained access control, rate limiting, and quota management per service
What's Included
Assessment & Planning
Week 1-2- Current microservices architecture analysis
- Service communication patterns mapping
- Performance and reliability requirements
- Service mesh technology selection (Istio, Linkerd, Consul)
- Migration strategy and rollout plan
Service Mesh Deployment
Week 3-10- Control plane installation and configuration
- Data plane (sidecar proxy) deployment strategy
- mTLS certificate authority integration
- Automatic sidecar injection setup
- Service discovery and registry integration
- Ingress and egress gateway configuration
Traffic & Security Configuration
Week 11-14- Traffic routing and load balancing policies
- Circuit breaker and retry configuration
- Rate limiting and quota policies
- Authorization policies and access control
- Fault injection for chaos engineering
- Progressive delivery workflows (canary, blue/green)
Observability & Operations
Week 15-16- Distributed tracing integration (Jaeger, Zipkin)
- Metrics and monitoring setup (Prometheus, Grafana)
- Service mesh dashboard configuration
- Alert rules and incident response
- Team training on service mesh operations
- Documentation and best practices
- 60-day post-launch support
Return on Investment
99.9% Encryption
Automatic mTLS for all service-to-service communication
50% Faster Debugging
Complete observability and distributed tracing
Zero-Downtime Deploys
Progressive delivery with automatic rollback capabilities
Investment
Starter
$25,000
Single cluster service mesh
- Single Kubernetes cluster
- Up to 20 services
- Basic mTLS configuration
- Traffic management policies
- Standard observability
- 8-10 week timeline
Most Popular
Professional
$45,000
Multi-cluster production mesh
- Multi-cluster mesh federation
- Up to 100 services
- Advanced traffic management
- Progressive delivery workflows
- Full observability stack
- Security policies and RBAC
- Team training
- 12-14 week timeline
Enterprise
$70,000+
Global service mesh platform
- Multi-region mesh deployment
- Unlimited services
- Multi-tenancy support
- Advanced security controls
- Custom integrations
- HA control plane
- Performance optimization
- 24/7 mesh operations support
- 14-18 week timeline
Ready to Deploy a Service Mesh?
Schedule a free 30-minute consultation to discuss your service mesh needs