Service Mesh: The Missing Infrastructure Layer for Microservices
Dennis Weston
November 30, 2025
Quick Navigation
- The Problem
- What is a Service Mesh
- Core Capabilities
- When You Need a Service Mesh
- Implementation Strategy
- Common Pitfalls
- Getting Started
The Problem
Your team has embraced microservices. You've decomposed your monolith into dozens of services. Each service is independently deployable, scalable, and maintainable. You're moving faster than ever.
Then the operational complexity hits.
How do you secure communication between 50 services? How do you implement rate limiting, retries, and circuit breakers consistently? How do you monitor traffic flows when requests traverse multiple services? How do you perform blue-green deployments or canary releases safely?
You could build these capabilities into every service. Many teams try. They end up with inconsistent implementations, duplicated code, and tight coupling between business logic and infrastructure concerns.
The Hidden Cost of Cross-Cutting Concerns
We've seen enterprises spend thousands of engineering hours reimplementing the same networking logic in every microservice:
- Service discovery - How does Service A find Service B?
- Load balancing - Which instance of Service B should handle this request?
- Retries and timeouts - What happens when a request fails?
- Circuit breakers - How do we prevent cascading failures?
- Mutual TLS - How do we encrypt and authenticate service-to-service traffic?
- Observability - How do we trace requests across service boundaries?
Each team solves these problems slightly differently, in different languages, with different libraries. When security policies change or new requirements emerge, you need to update dozens of services.
This doesn't scale.
What is a Service Mesh
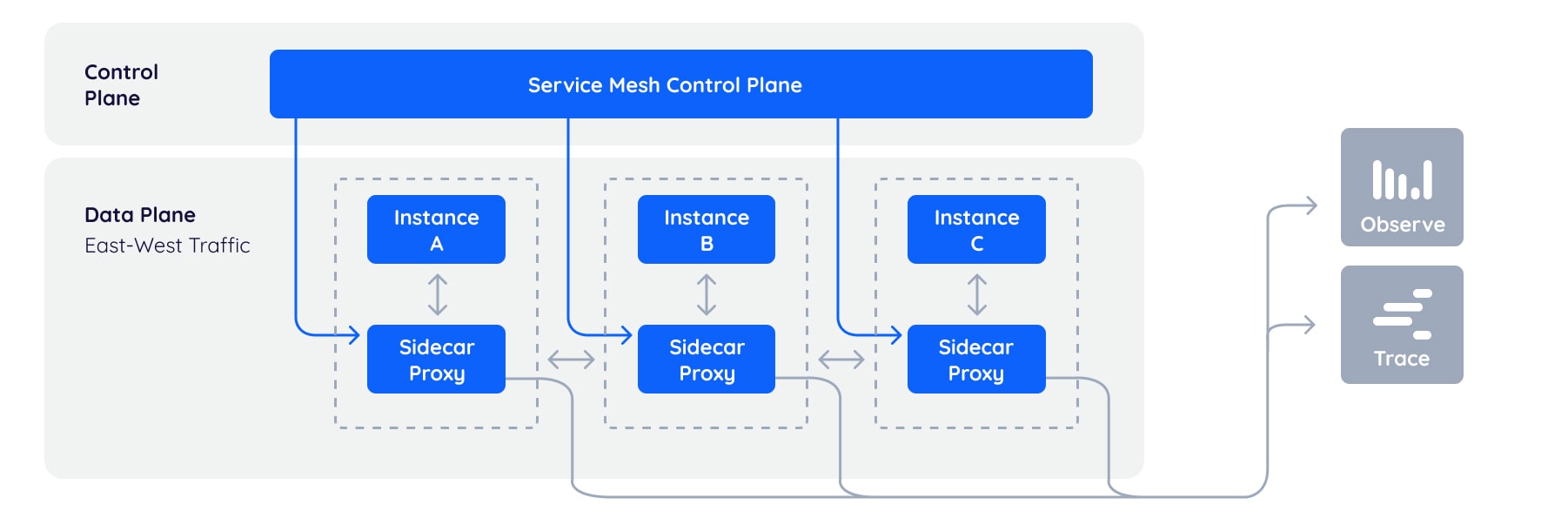
A service mesh is a dedicated infrastructure layer that handles service-to-service communication. It moves networking logic out of application code and into the infrastructure, where it can be managed consistently across all services.
How It Works
Service mesh architectures typically use a sidecar proxy pattern. Each service gets a lightweight proxy deployed alongside it (as a sidecar container in Kubernetes). All network traffic—both inbound and outbound—flows through this proxy.
The proxies handle:
- Encryption - Automatic mTLS for all service-to-service communication
- Routing - Intelligent traffic distribution based on rules
- Resilience - Retries, timeouts, circuit breakers
- Observability - Metrics, logs, and distributed tracing
- Security - Authorization policies and traffic encryption
Your application code doesn't know the mesh exists. It makes normal HTTP or gRPC calls. The sidecar intercepts these calls and applies policies transparently.
Control Plane vs Data Plane
Service mesh architecture separates concerns into two planes:
Data Plane - The sidecar proxies that handle actual traffic. These are high-performance, low-latency proxies (typically Envoy) deployed with each service instance. They execute the policies but don't define them.
Control Plane - The centralized management layer that configures the data plane. This is where operators define traffic rules, security policies, and observability settings. The control plane pushes configuration to all sidecars automatically.
This separation means you can update policies across hundreds of services by changing control plane configuration—no application deployments required.
Core Capabilities
Automatic Mutual TLS
Without a service mesh, implementing mTLS between microservices requires:
- Certificate generation for each service
- Certificate distribution and rotation
- Code changes to configure TLS in every service
- Management of trust relationships
With a service mesh, mTLS is automatic. The control plane generates certificates, distributes them to sidecars, and rotates them before expiry. Services get encrypted, authenticated communication without code changes.
This isn't just encryption. It's mutual authentication—both sides verify identity. Service A knows it's really talking to Service B, not an imposter. Service B knows the request came from authorized Service A, not a compromised service.
Traffic Management
Service meshes enable sophisticated traffic control without touching application code:
Traffic Splitting - Route 95% of traffic to stable version, 5% to canary. Gradually increase canary percentage while monitoring error rates. Instantly rollback if issues appear.
Request Routing - Route requests based on headers, cookies, or source service. Send beta users to new features while stable users hit production. Route internal traffic differently than external.
Load Balancing - Distribute traffic using various algorithms—round-robin, least request, consistent hashing. Automatically route around unhealthy instances.
Fault Injection - Deliberately inject latency or errors into specific routes to test resilience. Verify your services handle failures gracefully before failures happen in production.
These capabilities enable deployment patterns that are difficult or impossible without a mesh:
- Canary deployments with automatic rollback based on metrics
- A/B testing by routing user segments to different versions
- Shadow traffic to validate new services with production load
- Geographic routing to serve users from the nearest region
Resilience and Reliability
Network failures are inevitable in distributed systems. Service meshes provide automatic resilience:
Retries - Automatically retry failed requests with configurable backoff. The application doesn't need retry logic—the sidecar handles it transparently.
Timeouts - Enforce request deadlines to prevent resource exhaustion. If Service B is slow, Service A doesn't wait forever—the mesh enforces timeouts and returns errors quickly.
Circuit Breakers - Prevent cascading failures by temporarily blocking requests to unhealthy services. When Service C starts failing, the mesh stops sending traffic until it recovers, protecting both the failing service and its callers.
Rate Limiting - Protect services from overload by limiting request rates. Enforce different limits for different clients or request types.
Observability
Service meshes provide deep visibility into microservices communication:
Metrics - Automatic collection of request volume, latency, error rates for every service-to-service interaction. No custom instrumentation required.
Distributed Tracing - Trace requests as they flow through multiple services. Identify bottlenecks, understand dependencies, and debug production issues faster.
Service Graph - Visualize which services communicate with which. Understand your architecture at runtime, not based on documentation that's probably outdated.
Access Logs - Detailed logs of every request, including source, destination, response code, and latency. Essential for security auditing and troubleshooting.
This telemetry is consistent across all services, regardless of programming language or framework. Your Go services, Python services, and Java services all produce the same metrics format.
When You Need a Service Mesh
Service meshes solve specific problems. If you don't have these problems, you don't need a mesh.
Strong Indicators You Need a Service Mesh
You have 20+ microservices - Managing service-to-service communication manually doesn't scale beyond a dozen services. Once you have 20-50+ services, the operational complexity demands automation.
Security requires service-to-service encryption - Compliance mandates (PCI DSS, HIPAA, SOC2) increasingly require encrypted internal traffic. Implementing mTLS manually across dozens of services is expensive and error-prone.
Zero-trust architecture is a requirement - Modern security models assume the network is hostile. Every service must authenticate and authorize every request. Service mesh provides this by default.
You need sophisticated deployment patterns - Canary deployments, blue-green releases, and traffic splitting are difficult without a mesh. If safe, gradual rollouts are important to your business, a mesh enables them.
Observability gaps are blocking you - When incidents happen, can you trace requests across service boundaries? Can you identify which service in a chain is slow? If not, you need better observability.
Multiple teams own different services - When different teams control different parts of the system, enforcing consistent security and networking policies becomes critical. A mesh provides centralized policy management.
When You Don't Need a Service Mesh
You have fewer than 10 services - The operational overhead of a mesh outweighs the benefits. Use simpler approaches like API gateways and load balancers.
Your services are mostly independent - If services rarely communicate with each other, you don't have the service-to-service communication problem that meshes solve.
You're running a monolith - Service meshes are for microservices architectures. Monoliths don't need them.
You haven't mastered Kubernetes basics - A service mesh adds complexity. If you're still learning Kubernetes fundamentals, focus there first.
Implementation Strategy
Phase 1: Assess Readiness
Before implementing a service mesh, ensure your foundation is solid:
Container orchestration - Service meshes integrate deeply with Kubernetes. If you're not running Kubernetes, you're not ready for a mesh.
Service discovery - Your services should already discover each other dynamically. If you're still using hardcoded endpoints, fix that first.
Monitoring infrastructure - You need somewhere to send mesh telemetry. Ensure you have Prometheus, Grafana, or similar tools ready.
Team expertise - Service meshes introduce new concepts. Ensure your team understands sidecar proxies, mTLS, and traffic management basics.
Phase 2: Choose Your Mesh
The service mesh landscape has matured. Three major options dominate:
Istio - The most feature-rich option with broad adoption. Complex to operate but extremely capable. Best for large enterprises with dedicated platform teams.
Linkerd - Simpler and lighter than Istio. Easier to get started, fewer features. Good choice for teams wanting mesh benefits without operational complexity.
Consul - HashiCorp's service mesh with strong multi-cloud and multi-platform support. Works across Kubernetes and VMs. Best when you need a mesh beyond just Kubernetes.
AWS App Mesh, Google Traffic Director - Cloud provider offerings. Tight integration with provider services but vendor lock-in.
Choose based on your operational maturity, team size, and specific requirements. Start simple (Linkerd) unless you know you need advanced features.
Phase 3: Deploy Incrementally
Don't mesh everything at once. The blast radius of mistakes is too high.
Start with non-critical services - Choose services where failures won't impact customers. Learn the mesh in lower-risk environments.
Enable mTLS first - Get automatic service-to-service encryption working. This delivers immediate security value with minimal risk.
Add traffic management gradually - Once mTLS is stable, experiment with traffic splitting and routing rules on a single service.
Expand observability - Integrate mesh metrics with your monitoring tools. Build dashboards that show service-to-service communication patterns.
Move to production progressively - Mesh one production service, monitor for a week, then add another. Incremental rollout reduces risk.
Phase 4: Establish Governance
Service meshes enable powerful capabilities. Without governance, teams will use them inconsistently:
Define policies centrally - Who can create routing rules? Who approves security policies? Establish clear ownership.
Standardize configurations - Create templates for common patterns—canary deployments, retry policies, circuit breaker settings. Teams should start from approved templates.
Monitor mesh health - The mesh itself becomes critical infrastructure. Monitor control plane health, sidecar resource usage, and certificate expiration.
Plan for upgrades - Service mesh software evolves rapidly. Establish a process for testing and deploying mesh upgrades without disrupting applications.
Common Pitfalls
Underestimating Operational Complexity
Service meshes add moving parts. You now operate:
- Control plane components (multiple pods)
- Sidecar proxies in every service pod
- Certificate infrastructure
- Configuration management
Each of these can fail. Teams often underestimate the operational burden. Budget for dedicated platform engineering time.
Over-Configuring Too Early
The mesh offers hundreds of configuration options. New users try to configure everything upfront. This creates complexity without value.
Start with defaults. Only customize when you have a specific problem to solve. Most teams only use 20% of mesh features.
Ignoring Performance Impact
Sidecars add latency—typically 1-5ms per hop. For most applications, this is negligible. For latency-sensitive services, it matters.
Measure latency before and after mesh deployment. Optimize sidecar resource allocation. Disable features you don't need.
Skipping Security Hardening
The service mesh becomes a critical security control. If attackers compromise the control plane, they control all service traffic.
Secure the control plane with RBAC, network policies, and minimal permissions. Regularly rotate certificates. Monitor for unauthorized configuration changes.
No Rollback Plan
What happens if the mesh fails? Can you remove sidecar proxies quickly? Can services communicate without the mesh?
Test rollback procedures before you need them. Ensure you can bypass the mesh in emergencies.
Getting Started
If you're convinced a service mesh solves your problems, start here:
1. Set up a test environment - Don't experiment in production. Create a dedicated Kubernetes cluster for mesh evaluation.
2. Deploy a simple application - Use a sample microservices app (like Istio's Bookinfo demo) to learn mesh concepts without risking your own services.
3. Enable automatic mTLS - Configure the mesh to encrypt all service-to-service traffic. Verify encryption is working.
4. Visualize service communication - Deploy Kiali (for Istio) or Linkerd Viz to see traffic flows. Understanding the service graph is essential.
5. Implement a canary deployment - Deploy a new version of one service, route 10% of traffic to it, monitor metrics, then complete the rollout. This demonstrates real value.
6. Integrate observability - Connect mesh metrics to Prometheus and Grafana. Build dashboards showing request rates, latency, and errors.
7. Plan production rollout - Document lessons learned. Identify which services to mesh first. Create a rollout timeline.
Common Starting Points
Most teams begin with one of these use cases:
- mTLS everywhere for compliance requirements
- Canary deployments for safer releases
- Cross-cluster communication for multi-region architectures
- Service-to-service authorization for zero-trust security
Pick the use case that delivers the most value for your organization. Master it before expanding.
Work With Us
Tech Blend has deployed service mesh architectures for enterprises managing hundreds of microservices. We've implemented Istio, Linkerd, and Consul across multiple industries—healthcare, finance, and enterprise SaaS.
We help organizations:
- Assess service mesh readiness and choose the right solution
- Design and deploy mesh infrastructure with proper security controls
- Implement advanced traffic management for canary deployments and A/B testing
- Integrate observability into existing monitoring platforms
- Train platform teams to operate and troubleshoot the mesh
If your organization is evaluating service mesh or struggling with a deployment, we can help.
Get in touch: Email us at sales@techblendconsult.io
References
Want more insights like this?
Subscribe to get weekly DevSecOps guides, security best practices, and infrastructure tips delivered to your inbox.
No spam. Unsubscribe anytime.